Overview
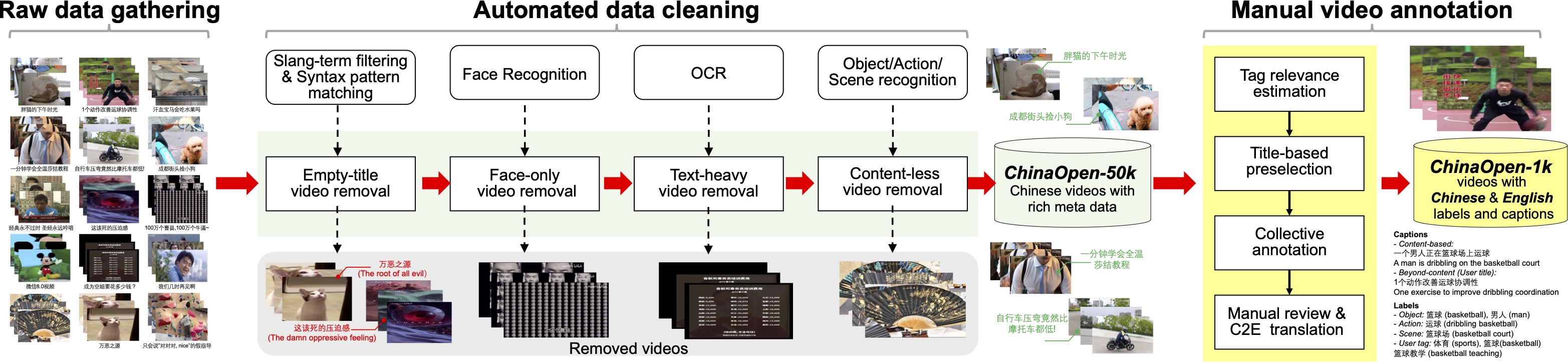
ChinaOpen is a new video dataset targeted at open-world multimodal learning, with raw data gathered from Bilibili, a popular Chinese video-sharing website. The dataset has a large webly annotated training set of videos (associated with user-generated titles and tags) and a smaller manually annotated test set of videos (with manually checked user titles / tags, manually written captions, and manual labels describing what visual objects / actions / scenes shown in the visual content).
[Research paper] [Source code]Milestones
[2023/12/08] ChinaOpen-1k (videos + annotations) is available at Hugging Face
[2023/07/27] The ChinaOpen paper accepted to the main track of ACMMM 2023!
[2023/05/31] Release the Generative Video-to-text Transformer (GVT) demo (Colab | Github) and checkpoints.
[2023/05/09] ChinaOpen-v1.0: ChinaOpen-50k for training + ChinaOpen-1k for test.